

This Credit Card Fraud Detection project aims to accurately identify fraudulent transactions within a highly imbalanced dataset, where only a small fraction of transactions are fraudulent. The dataset, available on Kaggle, contains over 284,000 credit card transactions with anonymized features, allowing for in-depth analysis without privacy concerns.
The project involves several critical steps to preprocess, analyze, and model the data to detect fraud effectively. Key phases include data cleaning, feature scaling, and addressing class imbalance through techniques like SMOTE and class-weight adjustments. A range of models will be tested, from logistic regression and decision trees to more advanced algorithms like random forests, gradient boosting, and autoencoders. Performance will be evaluated through metrics like precision, recall, F1-score, and ROC-AUC, with a focus on minimizing false positives while maximizing fraud detection accuracy.
Optional deployment through Streamlit or Flask will provide a practical interface, enabling users to test the model’s fraud detection capabilities in a real-world setting. This project will utilize tools like Pandas, Scikit-Learn, XGBoost, and Imbalanced-learn to create a robust fraud detection system that can aid in protecting credit card users and financial institutions.
Steps taken to analyze the data and to build the model:
- Download the dataset from [Kaggle’s Credit Card Fraud Detection dataset](http://www.kaggle.com/datasets/mlg-ulb/creditcardfraud). This dataset contains anonymized credit card transactions labeled as fraudulent or legitimate.
- Inspect the Dataset: It has 284,807 transactions, with only 492 labeled as fraud (about 0.17%), making it highly imbalanced.
- Run the following code in Visual Studio or any other tool:
import pandas as pd
# Load the dataset
df = pd.read_csv('creditcard.csv')
# Inspect the data
print(df.head())
print(df.info())
print(df.describe())
The data file was tagged with column headers that were V 1, V2, V3 etc. This data set does not give a good sense of the features on the data file.
4. Pre-process the data set (check for missing, null values etc.)
# Check for missing values
print(df.isnull().sum())
In thedata set there were zero missing values
5. Scale the columns if needed. A way to identify columns to scale would be to get the mean of each column and identify any large variances compared to the other columns. In this case the distribution of Amount was large.
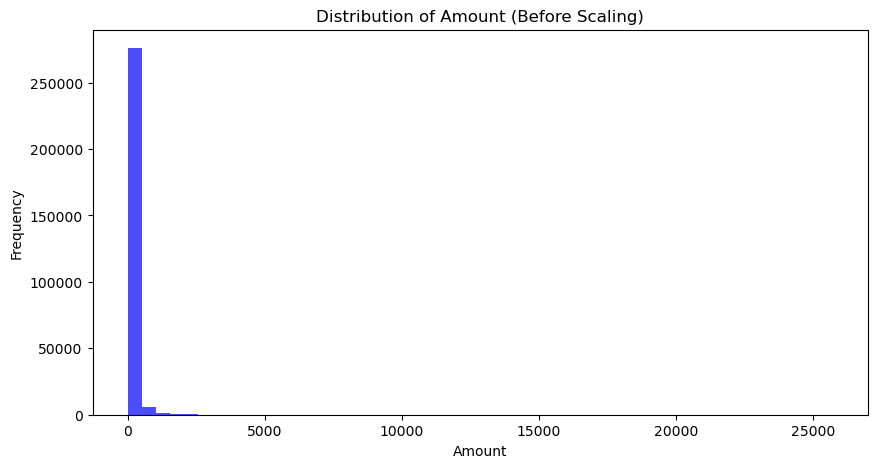
Scale the amount feature using the standardscalar from the sklearn library
from sklearn.preprocessing import StandardScaler
# Scale the 'Amount' feature
scaler = StandardScaler()
df['Amount'] = scaler.fit_transform(df[['Amount']])
# Drop 'Time' feature if it's not useful in your model
df = df.drop(columns=['Time'])
6. Split the Dataset
The purpose of using train_test_split in this code is to divide the dataset into training and testing subsets, allowing you to build and evaluate your model effectively. Here’s a summary of why each step is essential:
Define X and y:
Xrepresents the features of the dataset (all columns except the target variable,Class).yrepresents the target variable (Class), which indicates whether a transaction is fraudulent or legitimate.
Split the Data:
train_test_splitsplits the data into training and testing sets.
Training Set (80%): Used to train your model so it can learn patterns from the data.
Testing Set (20%): Held out to test the model’s performance on unseen data, providing a realistic measure of accuracy.
Stratify
y: Ensures that the target variable (Class, which is highly imbalanced) has the same distribution in both the training and testing sets, preserving the ratio of fraud to non-fraud cases. This helps the model perform better on the imbalanced dataset.
Using train_test_split in this way ensures your model has a solid training foundation and a reliable method for evaluation.
from sklearn.model_selection import train_test_split
# Define X and y
X = df.drop(columns=['Class']) # Features
y = df['Class'] # Target variable
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
7. Handle Class Imbalances
One of the biggest problems with the data set as mentioned at the beginning of the article is that it has 284,807 transactions, with only 492 labeled as fraud (about 0.17%), making it highly imbalanced.
Addressing class imbalance is essential for improving model performance, especially in cases where a dataset has very few samples of a minority class, like fraud detection. Here are some popular techniques to handle imbalanced datasets:
Oversampling Techniques
- Synthetic Minority Over-sampling Technique (SMOTE):
- SMOTE generates synthetic samples for the minority class by interpolating between existing samples and their nearest neighbors.
- This increases the presence of the minority class in the training dataset without duplicating existing samples.
- It’s particularly effective as it reduces the chances of overfitting that can occur with simple random oversampling.
- Random Oversampling:
- In random oversampling, minority class samples are randomly duplicated until the classes are balanced.
- While simple, it can sometimes lead to overfitting since the model might “memorize” the duplicated samples.
- ADASYN (Adaptive Synthetic Sampling):
- ADASYN builds on SMOTE by focusing on generating more synthetic data for minority class samples that are harder to classify.
- It’s useful for highly complex datasets with significant class overlap.
Undersampling Techniques
- Random Undersampling:
- Randomly removes samples from the majority class to balance the dataset.
- This technique can risk losing valuable information from the majority class, potentially reducing model performance.
- Tomek Links:
- Tomek Links identify pairs of samples from opposite classes that are closest to each other. One sample from each pair (usually from the majority class) is removed.
- This technique can make the decision boundary between classes clearer.
- Cluster Centroids:
- Replaces clusters of majority class samples with centroids, effectively reducing the sample count in the majority class while retaining some structure.
Class Weight Adjustment
- Assign Class Weights:
- Many machine learning algorithms, such as
Logistic Regression,Random Forest, andSVM, allow adjusting class weights to give more importance to the minority class. - By setting
class_weight='balanced', these models automatically adjust the class weight based on the distribution of classes, helping the model focus more on the minority class.
4. Ensemble Methods
- Balanced Random Forest and EasyEnsemble:
- Balanced Random Forest combines random undersampling with ensemble methods, using multiple decision trees to improve performance on imbalanced data.
- EasyEnsemble uses multiple random undersampled subsets of the majority class to create a balanced training dataset, then trains an ensemble of classifiers on each subset.
5. Anomaly Detection Algorithms
- Autoencoders and Isolation Forests:
- For severe imbalance where the minority class is considered an anomaly, anomaly detection methods can be effective.
- Autoencoders, for instance, can be trained only on majority class data. Any instance that differs significantly from this majority data is flagged as an anomaly.
8. Run the models
There are a couple of models that were run: Logistic Regression Model, Decision Tree Model, K-nearest neaighbours, Random Forest Classifier, XGBoost and Auto Encoder.
Here is the why behind the models and why they were used in this
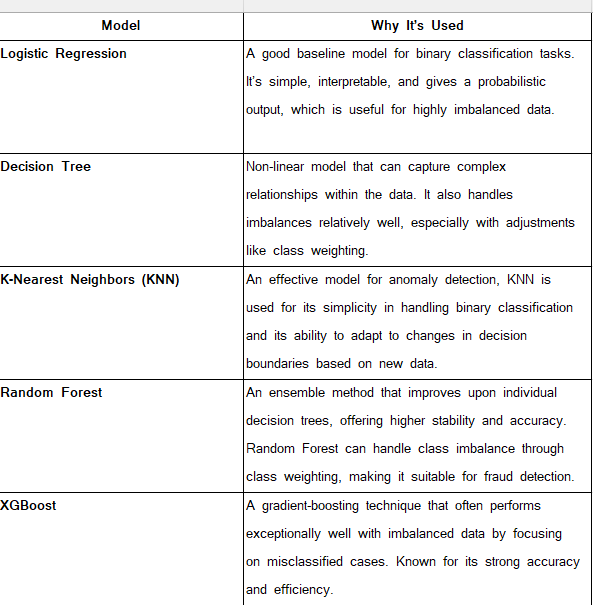
Here are the results of the models:

1. Logistic Regression
- Accuracy: 0.974562
- Precision: 0.058785
- Recall: 0.918367
- F1 Score: 0.110497
- ROC AUC: 0.971447
Analysis: Logistic Regression shows a high recall (0.918367) and a good ROC AUC score (0.971447), indicating it’s effective at identifying actual fraud cases. However, it has a low precision (0.058785) and F1 Score (0.110497), meaning it produces many false positives. This model is suitable if you prioritize identifying as many fraud cases as possible but can tolerate a high false positive rate.
2. Decision Tree
- Accuracy: 0.998999
- Precision: 0.707071
- Recall: 0.714286
- F1 Score: 0.710660
- ROC AUC: 0.856888
Analysis: The Decision Tree model has a balanced performance between precision and recall (both around 0.71) with a high accuracy (0.998999). It offers better precision than Logistic Regression, meaning fewer false positives, but lower recall, so it may miss some fraud cases. It’s a more balanced choice for situations where both precision and recall matter.
3. Random Forest
- Accuracy: 0.999526
- Precision: 0.961039
- Recall: 0.755102
- F1 Score: 0.845714
- ROC AUC: 0.958013
Analysis: Random Forest shows high precision (0.961039), indicating that most fraud predictions are accurate. Its recall (0.755102) is also relatively high, meaning it captures a significant number of fraud cases. With a high F1 score (0.845714) and ROC AUC (0.958013), this model offers a good balance of precision and recall, making it one of the best choices overall for this task.
4. XGBoost
- Accuracy: 0.999544
- Precision: 0.882979
- Recall: 0.846939
- F1 Score: 0.864583
- ROC AUC: 0.969123
Analysis: XGBoost has high precision (0.882979) and recall (0.846939), making it the best-performing model in terms of balancing both false positives and false negatives. It has a high F1 score (0.864583) and an excellent ROC AUC (0.969123), indicating strong overall performance. XGBoost would be the top choice if you aim for both high precision and high recall in detecting fraud.
5. K-Nearest Neighbors (KNN)
- Accuracy: 0.999508
- Precision: 0.897727
- Recall: 0.806122
- F1 Score: 0.849462
- ROC AUC: NaN (Not applicable without probability scores)
Analysis: KNN offers high precision (0.897727) and reasonable recall (0.806122), similar to the Random Forest but slightly lower in recall. Its accuracy and F1 score are high, suggesting good performance, but the lack of a ROC AUC score limits a full evaluation. KNN is a viable option, especially if you prefer a non-parametric model, but its performance is slightly below that of XGBoost and Random Forest.
Overall Recommendations
- Best Model: XGBoost achieves the best balance of precision and recall, with strong scores across all metrics.
- Alternative: Random Forest is a close second, with slightly higher precision but a bit lower recall compared to XGBoost.
- If Recall is Critical: Logistic Regression has the highest recall but very low precision, making it suitable if detecting every fraud case is more important than reducing false positives.
For your task, the goal is to minimize both false positives and false negatives, XGBoost would likely be the best choice.
Some notes about the metrics used:
1. Accuracy
- Definition: The proportion of correct predictions (both true positives and true negatives) out of the total number of predictions.
- Formula: Accuracy=True Positives+True NegativesTotal Predictions\text{Accuracy} = \frac{\text{True Positives} + \text{True Negatives}}{\text{Total Predictions}}Accuracy=Total PredictionsTrue Positives+True Negatives
- Interpretation: Measures overall correctness, but can be misleading with imbalanced datasets, as it doesn’t account for the different importance of positive and negative classes.
2. Precision
- Definition: The proportion of true positive predictions out of all positive predictions (true positives + false positives).
- Formula: Precision=True PositivesTrue Positives+False Positives\text{Precision} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Positives}}Precision=True Positives+False PositivesTrue Positives
- Interpretation: Precision indicates the accuracy of positive predictions. High precision means fewer false positives. It’s particularly important in scenarios where the cost of false positives is high, such as fraud detection, where incorrectly labeling a legitimate transaction as fraud should be minimized.
3. Recall (Sensitivity or True Positive Rate)
- Definition: The proportion of true positive predictions out of all actual positives (true positives + false negatives).
- Formula: Recall=True PositivesTrue Positives+False Negatives\text{Recall} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}}Recall=True Positives+False NegativesTrue Positives
- Interpretation: Recall measures the ability to capture all actual positive cases. High recall means fewer false negatives. It’s crucial in cases where missing a positive case (such as undetected fraud) has severe consequences.
4. F1 Score
- Definition: The harmonic mean of precision and recall, combining them into a single metric.
- Formula: F1 Score=2×Precision×RecallPrecision+Recall\text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}F1 Score=2×Precision+RecallPrecision×Recall
- Interpretation: The F1 score provides a balanced measure of precision and recall, especially useful in imbalanced datasets. A high F1 score means the model achieves both high precision and recall, which is ideal in situations like fraud detection where both false positives and false negatives are important.
5. ROC-AUC (Receiver Operating Characteristic — Area Under the Curve)
- Definition: The area under the ROC curve, which plots the true positive rate (recall) against the false positive rate at various threshold levels.
- Range: 0.5 to 1.0, where 0.5 is no better than random guessing, and 1.0 is a perfect model.
- Interpretation: ROC-AUC represents the model’s ability to distinguish between classes. A higher ROC-AUC score indicates better discrimination between positive and negative classes. This metric is useful for evaluating imbalanced datasets because it focuses on ranking positive cases higher than negative ones, rather than accuracy alone.
To view the code click here: rlis123456/CreditcardFraudDetection: Project to Detect Fraud from Transactions (github.com)
